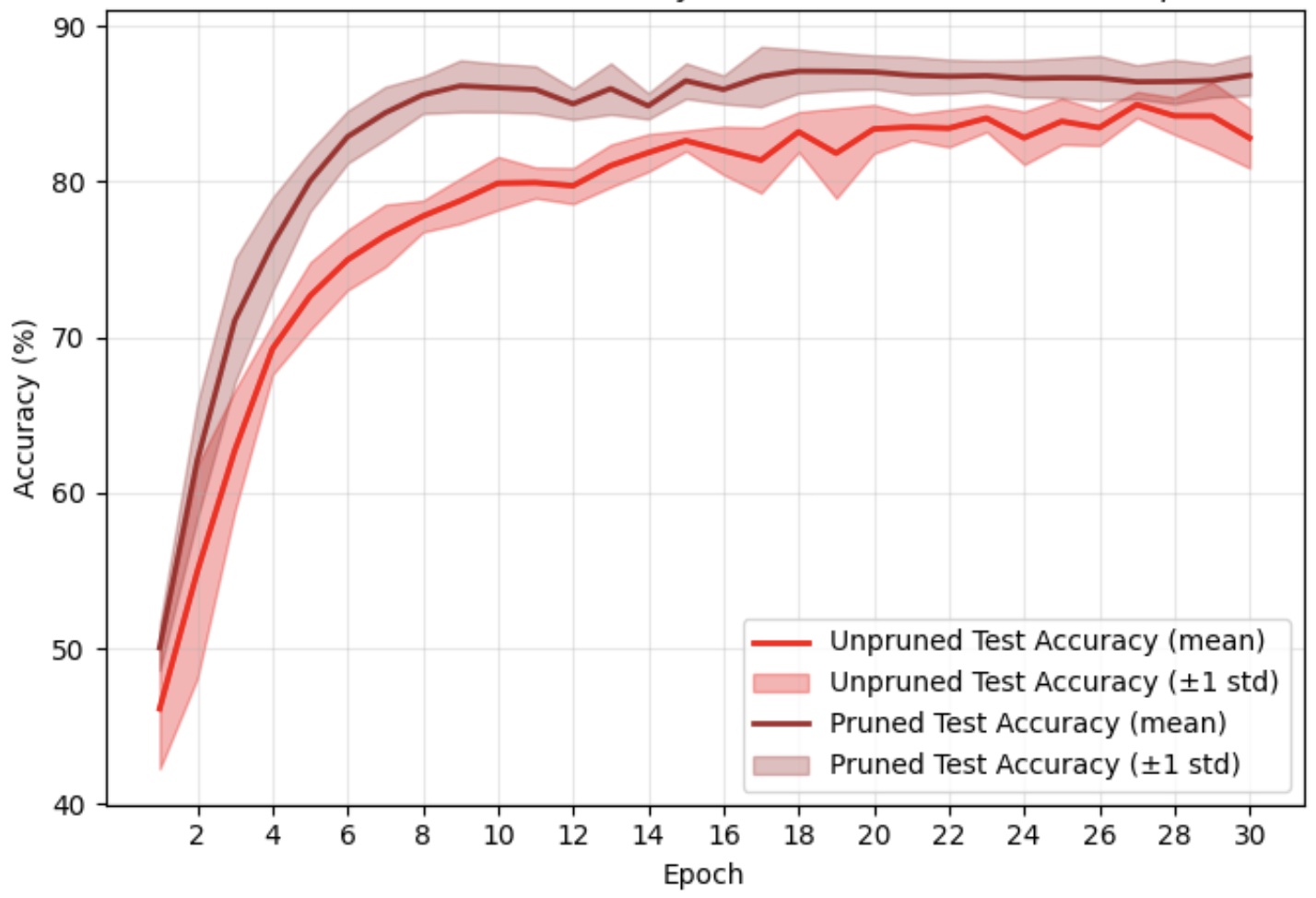
Deep neural networks often achieve state-of-the-art performance by relying on substantial parameter counts, which can make training and deployment costly in memory and compute. Pruning aims to reduce this redundancy by removing parameters that contribute little to the model’s predictions. This paper proposes a novel mid-training pruning scheme that uses the Fisher Information Matrix (FIM) and gradient directions to identify removable parameters while training is still ongoing. Rather than pruning only after convergence, this method interleaves optimization with pruning by estimating parameter importance via efficient estimation of an augmented FIM and progressively masks low-score weights as learning continues. This produces a sparsity trajectory that adapts to the model’s evolving sensitivity, enabling earlier and more aggressive compressions with reduced performance loss. This paper benchmarks the approach against unpruned baselines, evaluating final accuracy, training stability, and finds that augmented FIM-based mid-training pruning better preserves accuracy.